LiveSpeech: Low-Latency Zero-shot Text-to-Speech via Autoregressive Modeling of Audio Discrete Codes
Trung Dang, David Aponte, Dung Tran, Kazuhito Koishida
Applied Sciences Group, Microsoft Corporation
[arXiv]
Abstract
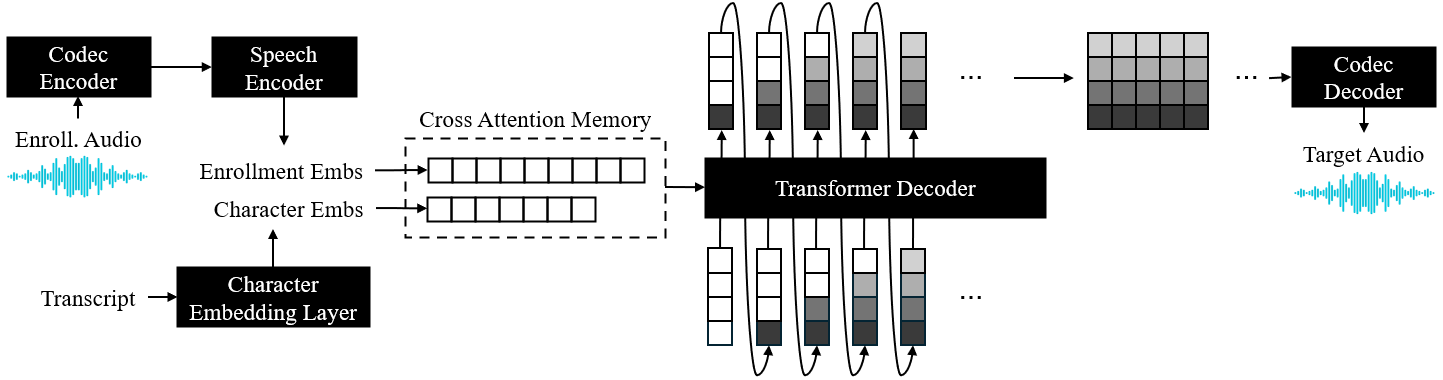
Prior works have demonstrated zero-shot text-to-speech by using a generative language model on audio tokens obtained via a neural audio codec. It is still challenging, however, to adapt them to low-latency scenarios. In this paper, we present LiveSpeech - a fully autoregressive language model-based approach for zero-shot text-to-speech, enabling low-latency streaming of the output audio. To allow multiple token prediction within a single decoding step, we propose (1) using adaptive codebook loss weights that consider codebook contribution in each frame and focus on hard instances, and (2) grouping codebooks and processing groups in parallel. Experiments show our proposed models achieve competitive results to state-of-the-art baselines in terms of content accuracy, speaker similarity, audio quality, and inference speed while being suitable for low-latency streaming applications.
Samples
| Transcript | Enrollment | Reference | YourTTS | SpeechX | Ours (8-group) | Ours (8-group) + Enhancer |
| the beggar's plea the politician's sceptre and the drummer's ablest assistant | ||||||
| that's not much of a job for an athlete | ||||||
| i am not complaining that the rate is slow but that the sea is so wide | ||||||
| what are they about thought the tree | ||||||
| at most by an alms given to a beggar whose blessing he fled from he might hope wearily to win for himself some measure of actual grace | ||||||
| how could you possibly know that | ||||||
| miss smith represented the older new england of her parents honest inscrutable determined with a conscience which she worshipped and utterly unselfish | ||||||
| he obtained the desired speed and load with a friction brake also regulator of speed but waited for an indicator to verify it | ||||||
| i will on one condition |